论文阅读 Detecting Peering Infrastructure Outages in the Wild

概述
从作者信息中可以看出这项工作是CAIDA发起的。
文章通过一种 被动测量方式,利用了BGP的Community属性提供的信息,来检测、定位、追踪基础设施级别上的中断。
背景
Prior Works
如今,我们的经济和我们的社会生活,都依赖于互联网的平稳和不间断的运行。虽然互联网整体上表现出了良好的弹性,但即使是短暂的中断Outage也会对一部分互联网用户产生重大影响。
以往的工作对各种源头造成的中断进行了深入的研究,如 硬件\软件\配置错误导致的 router outage路由中断、optical layer outages(链路中断)、自然灾害、全球审查。
而本文对 peering infrastructure 级别的中断进行了研究
互联网层级的扁平化
问:什么是 peering infrastructure 呢?
近年来,互联网基础设施发生了显著变化,互联网层级开始“扁平化”。“扁平化”意味着大多数互联网域间流量直接在边缘网络之间流动,不经过传输提供商(transit provider)。
具体以下图说明:
ISP可以从互联网管理机构申请到很多IP地址,然后一些机构和个人从某个ISP获取IP地址的使用权,并可通过该ISP连接到互联网,本地ISP给用户提供最直接的服务,本地ISP可以连接到地区ISP,也可以连接到主干ISP,这就形成了一个互联网层级结构。
由于这样的等级结构,使得大多数的局部中断只会造成局部影响。
为了更快地转发流量,IXP允许两个网络直接连接并交换分组,而不需要经过第三个网络来转发分组,这就使得网络结构变得扁平化。
图中,主机A和主机B通过2个地区ISP连接起来了,就不必经过最上层的的主干ISP来转发分组。典型的IXP由一个或多个网络交换机组成。
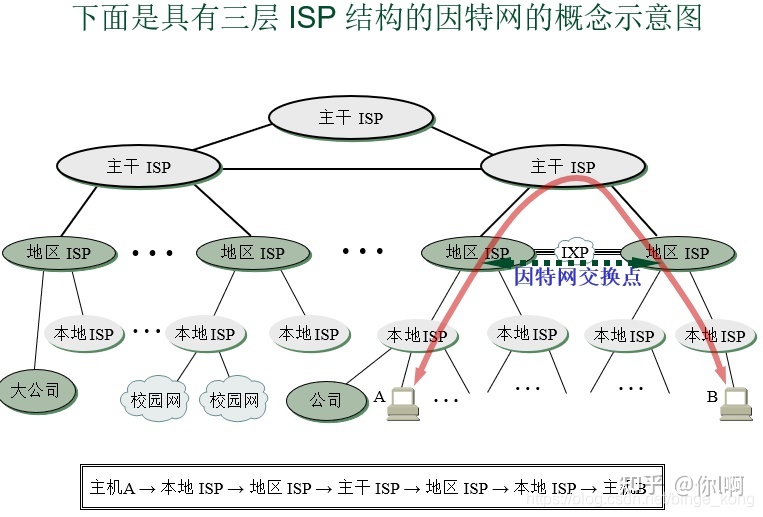
答:像 IXPs 这样支持 直接对等连接 的第三方基础设施就是 peering infrastructure。
Peering Infrastructure
本文讨论的基础设施主要包括两种:IXPs、Colocation Facilities
- Internet Exchange Points (IXPs) —— 不同运营商之间为连通各自网络而建立的集中交换平台,一般由第三方中立运营
- Co-location Facilities (CFs) —— 主机托管为租户提供服务器或网络设备的托管,也支持了大量的直接对等连接
二者都是互联网的重要基础设施,这样基础设施级别的中断往往会对大量网络造成影响,但是却很少有工作研究发生在这些基础设施中的中断。
目标
文章想要解决的问题,是能够检测、定位、追踪infra-level的中断,以下我们用一个例子来明确达成这样一个目标要做的事情。
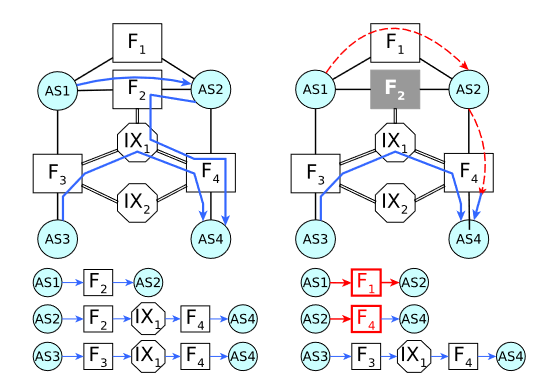
- 检测到发生了基础设施级别的中断
- Challenge:依赖于AS级别的测量,我们是无法推断出infra级别的中断的,如图,Facility2故障时,AS1->AS2和AS2->AS4的路径发生了变化,但是它们的AS PATH却没有改变。
- Insight:本文希望通过BGP的community属性得到额外的信息,来判断路径中基础设施是否发生了变化。
- 定位发生中断的位置
- Challenge:当发现infra-level的路径发生了变化,需要判断是路径中的哪一个基础设施发生了变化,如图,如果只观察AS2->AS4,是无法确定F2、IX1、F4哪个设施发生了中断。
- Insight:需要从多个VP进行观察多个路径,如图,F2从所有路径中消失了,但是IX1只从经过F2的路径中消失了,以此来推断是F2发生了中断。
- 追踪观察中断的持续时间及其影响
- Insight:需要记录中断发生前的稳定的路径状态,然后持续监控,观察是否发生了路径偏离。
具体方法及原理
(补充概括)
BGP Communit Dictionary
BGP的Community属性
- 格式:16bit的ASN :16bit的路由入口地址(共32bit)
- 类型:inbound communities (当AS接收到一个前缀宣告时的入口接入点)、outbound communities (当AS宣告前缀时的出口接入点)
通过Community属性我们可以结合AS PATH还原出一条基础设施级别的路径。
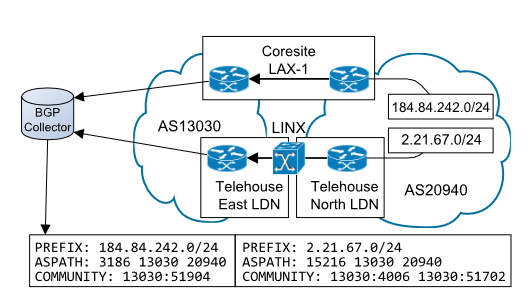
如下图,BGP collector接收到了来自前缀184.84.242.0/24、2.21.67.0/24宣告的路由信息,其中AS subpath为13030 20940,第一个路由信息的Community属性为13030:51904,其中13013表示了AS13030已经应用了Community属性,51904表示这个路由信息是从Coresite LAX-1 facility收到的;同理,第二个路由信息有两个Community属性,前16bit的13030表示AS13030应用了Community属性,51702表示该路由信息来自于Telehouse East London facility,4006表示该路由信息来自于对等设施LINX IXP Juniper LAN。
Community Dictionary
越来越多的网络选择使用Community属性,这些community属性中编码了大量路由元数据,可惜的是BGP Community是唯一未规范化具体语义的BGP属性。因此我们需要每个Community它的解析标准,才能从其中提取出我们需要的信息。
网络管理员会将他们网络的Community属性的设计规则发布在IRR记录中或他们的官方网站上,这些规则可能是一些没有统一规范的自然文本,因此文章开发了一个网络挖掘共工具,来爬取网站上的数据并解析。
- 使用 Web Scraper 来从IRR记录和相关网站上爬取Community相关设计规则
- 使用 Natural Language ToolKit 来解析提取出的文本信息,找到到infra-community相关的文本
- 使用正则表达式来匹配包含 Community 值的子串,并使用Stanford的Named Entity Recognizer来标识命名实体
- 得到的 Community Ditionary 中分了三种类型的命名实体:City-level、IXP、CF
- 为了提高准确性,文章还搜索了PeeringDB、Euro-IX和IRR记录,来确定识别出的实体的网络类型
- 使用 IXP Path Distribution 来扩充 Community Dictionary,IXP 路由服务器经常使用Community属性来帮助它连接的成员更好的将其前缀发布给其它成员
- 截至于2016年12月,该 Community 字典包括了从 468 个自治域发布的 5248 communities,48个路由服务器,覆盖了72个国家的288个城市,172个IXPs和103个CFs
- 为了保证最新,Community Dictionary每两周重新计算一次,并且总是使用对应时间段的字典进行路由处理
- 为了验证自动生成的社区字典的正确性,我们将其与手动构造的字典(仅包括最多BGP PATH标记的25ASes)进行了比较,没有误报和漏报
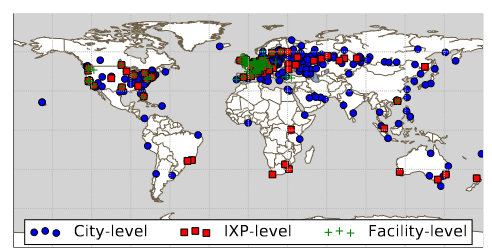
Colocation Map
在文章提取出的 Community 属性中,很大一部分是在city级别标注的,这个粒度太粗了,是无法在facility级别或ixp级别上确定中断的。
为了更精确更细粒度地定位,文章使用了一个高分辨率的 co-location map 来补充 BGP community,它包括三种类型的互连:AS to Facilities、AS to IXPs、IXPs to Facilities
如何构造这张 Colocation Map 呢?
通过对 PeeringDB、DataCenterMap、operator websites 等数据源的挖掘,可以得到每个 facility 的具体地址位置,这样我们就知道哪些 facility、ixp 和 ASes 在我们的 Community Ditionary 标注的城市中运行。
然后,合并每个数据源中列出的同一facility的租户,以增加 colocation map 的完整性。
在 city-level 中断信号发生时使用构建的 colocation map,根据中断是不是在facility中发生,区分开同一城市中各ASes受到的影响(??不太明白)。
因此,我们可以精确定位中断发生的可能的facility-level或ixp-level的位置,并将中断检测功能的检测粒度精确到物理位置,而不仅仅是BGP Community中显式编码的位置。
Detection Methodology
文章使用如下算法来检测和定位infra级别的中断

- inputs:a stream of BGP data
- 解析BGP Community,将BGP路径映射到经过的PoPs(Point of Presence —— city、IXP、CF)上
- 我们过滤掉顺态路径,以记录一个稳态路径
- 监测BGP UPDATE消息,来观察PoP-level上的路径偏离
- 当足够多的PoP偏离出现了,我们将其视为一个outage signal(这个中断信号只能说明中断发生时这个PoP受到了影响,不能定位为此处发生了中断)
- 根据受影响的ASes和它们的关联程度,来推断这个中断信号的类型PoP-level/AS-level/link-level
- 若是由PoP outage导致的signal,需要先用colocation map来确定具体是哪一种基础设施,并用traceroute进行验证
- outputs:info of a PoP-level Outage
Kepler系统
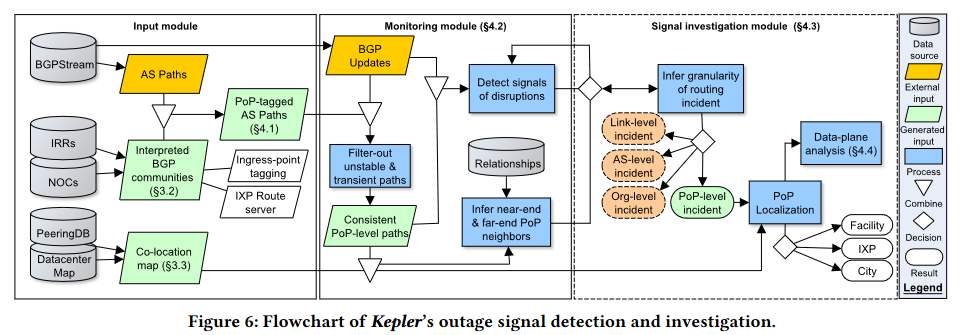
文章构建了一个kepler系统来实现上述算法,这个系统主要分为三个模块
Input Module:Data Processing 输入模块:数据预处理
生成了BGP Community Dictionary
生成了Co-location Map
对于每个带有Community属性的BGP UPDATE消息,使用Community Dictionary来推断经过的PoP
结合AS PATH得到了PoP-taged AS PATH
Monitoring Module:Outage Detection 检测模块:中断检测
持续监测community dictionary中所有的PoPs
周期性计算经过各个PoPs的稳定的路由路径
检查偏离基本稳定路径的PoPs改变
触发中断信号
Outage Signal Investigation 信号调查模块:确定中断的类型及具体位置
考虑在一个时间间隔内的所有中断信号,并确定触发中断的类型
- link-level, AS-level, operator-level, and PoP-level outages
对于PoP-level的事件,确定是哪一种基础设施,并定位具体物理位置
用traceroute验证后,追踪路径偏移到回复稳定路径的时间,来确定中断的持续时间
Data-Plane Analysis 数据平面分析:验证检测到的中断
kepler通过数据平面的分析来验证推断的PoP-level的中断:
初始化一系列稳态路径
当kepler检测到一个PoP outage时,它会识别通过该PoP互连的AS对的稳态路径
然后选择相同的源和目的地,并重复traceroute查询
如果持续通过PoP的基线路径的比例低于阈值Tfail,则确认中断并继续探测以确定中断的持续时间
否则,要么该中断推断为误报(假阳性),要么是在短时间内中断立即恢复了
评价 Kepler 系统的表现
(待补充)
结果
文章使用kepler系统来检测评估过去五年中peering infrastructure outages的影响
检测到的facility outages
文章对2012年到2016年的归档BGP stream和PeeringDB历史数据进行分析。
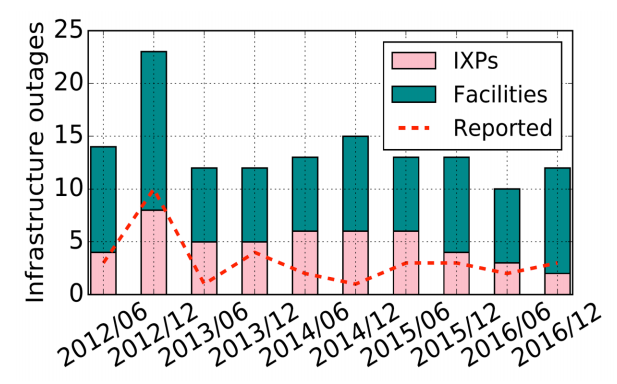
- 总共监测出了 159 个中断,其中103个中断发生在了87 个facilities上,56个中断发生在了41个 IXPs
- 其中有76%的中断是没有通过邮件或者网站报道出来的
- 53%的中断发生在欧洲,31%的中断发生在美国,剩下的分布在其它地区
- 五年中检测到的中断数量并没有明显上升
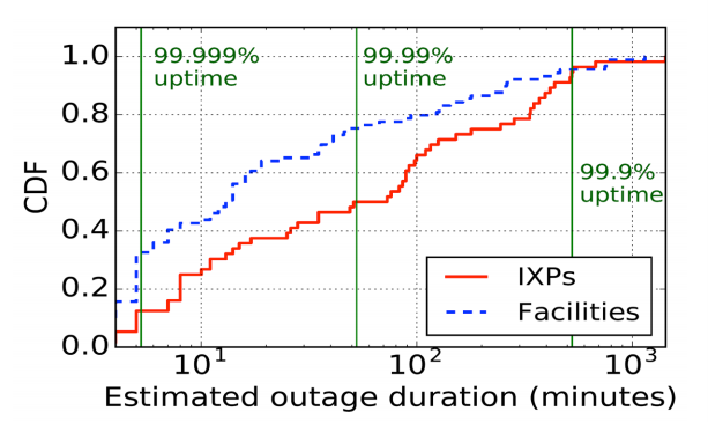
- 中断持续时间的中位数为17分钟,40%的中断时间超过1小时
- IXP的中断持续时间比facility的要长。推测原因是 大多数facility中断是由于电力或光纤切断,而IXP中断还可能是由于软件或配置错误,这会使得恢复花费较多的时间
- (图没看懂,99.999%uptime意味着啥???)
案例研究
为了展示kepler的探测能力,文章用三个中断案例的具体细节来说明
- The first one occurred at AMS-IX,a major IXP in Amsterdam, NL, at 2015-05-13.
这个中断是在维护期间由于交换机环路引起的,下图绘制了三个不同聚合级别的路径变化占比。
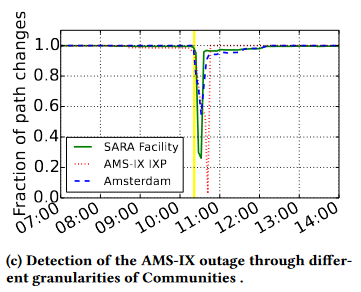
这次中断导致IXP丢失了几乎所有线路和超过90%的交换流量约10分钟。流量恢复大约花了15分钟。在所有聚合级别中都可以清楚地看到该事件,但AMS-IX Communities标记的路径显示了最大的下降,表明了中断的实际来源。
- The other two independent facility-level outages occurred in London.
这两个中断分别发生在 the co-located London-IXP LINX、a third facility TH East,如下图所示
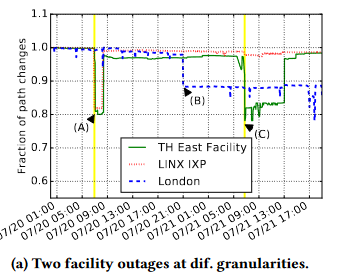
在A时刻,当第一次中断发生时,我们几乎看不到城市级别聚合的变化,而LINX和TH East都受到了影响。
在B时刻,我们观察到了一个city-level信号,这不是由于facility中断导致的,而是由于一个主要一级AS的路径重路由导致。
在C时刻,第二个中断发生了,我们可以看到TH East那条线有个大幅下降。
开普勒正确地识别了A和C信号为PoP outage的信号,识别B信号为AS导致的信号,而不是推断LINX或TH East作为潜在的中断源。而后通过检查中断对远端ASes的影响,对这些ASes所关联的设施进行信号定位,如下图所示
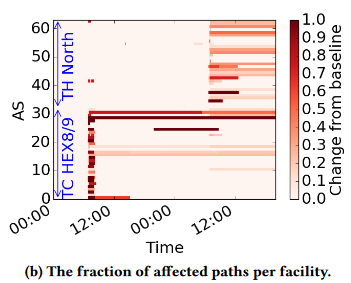
很明显,A和C时刻,在 TC HEX8/9 和 TH North 的 ASes 的两个主要子集受到了影响,而伦敦其他设施的远端ASes(未描述)没有显示同时中断的迹象,这使我们能够正确地识别 TC HEX8/9 和 TH North 作为中断源。
我们可以看到,在时刻B,只有一个AS受到影响。该图还体现了ASes处理中断的方式不同,一旦中断结束,一些会返回到他们的“稳定”路径,而另一些则继续使用新的路径。这组停机说明了开普勒消除设备停机信号来源歧义的能力。
主动探测
文章希望体现在kepler系统中加入主动探测方式的好处,接下来以发生在AMS-IX的中断举例。
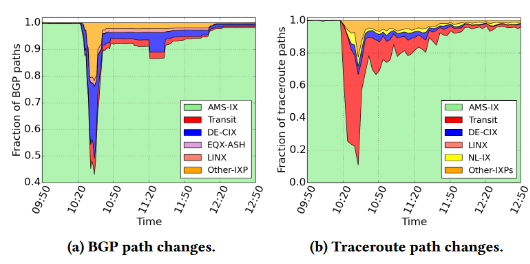
上图展示了中断发生时,BGP path的改变和traceroute path的改变,虽然总体路径变化趋势一致,但激活的备份路径不同。BGP Community主要由具有非常多样化对等连接的大型ASes提供,允许它们在远程ixp上激活可选对等链路;另一方面,大多数 traceroute 探测驻留在本地的ASes中,因此大多数,即75%的备用路由是通过transit 互连的。
BGP路径重新收敛大约花了4个小时,直到95%的路径返回。大约5%的路径甚至在中断几天后都没有恢复。这种永久的路由变化要么是由于人工干预,要么是由于BGP决策过程倾向于使用最新的路径来打破束缚减少路由振荡。尽管85%的traceroute路径在一小时内返回AMS-IX,但仍有相当一部分继续穿过transit link。这些结果表明,中断对控制平面和数据平面路由路径的实际影响远远比中断的持续时间久。
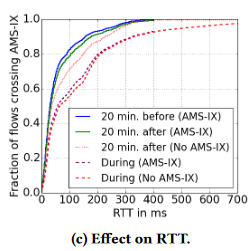
Kepler还使用traceroute数据在往返时间(RTT)内评估中断的影响。虽然我们承认来自traceroute的rtt可能无法直接等同TCP所看到的rtt,但它们可以作为性能变化的指示。上图显示了通过AMS-IX的路径的RTT延迟的经验累积分布函数。
文章区分了三个时间段:(i)中断前20分钟,(ii)中断期间,以及(iii)中断后20分钟,即操作恢复正常后10分钟。此外,我们将路径划分为在中断期间和之后使用AMS-IX和不使用AMS-IX 的路径。
(????不懂)在中断期间,重路由路径的中位数RTT上升超过100毫秒。对于不变的路径,中值RTT的增加是适度的,虽然有一些路径经历了显著的增加,但靠后的时间里没有增长那么多。在中断之后,这个RTT增加消失了。此外,在20分钟内返回AMS-IX的路径所经历的RTT与中断前大致相同。然而,由于在距离方面的次优路由,仍然使用替代互连的30%的路径 持续有大约40毫秒的rtt增加。
远端的影响
为了了解基础设施中断的影响,我们研究了前文提到的两次伦敦中断,分析这两次中断影响的ASes的位置。我们使用DRoP定位由Kepler的traceroute识别的受影响ASes的远端接口的ip。
上图以公里为单位绘制了到伦敦的距离与受影响的ASes的数量的关系。令人惊讶的是,只有44%的远端接口也在伦敦。超过45%的接口在其他国家,超过20%的接口在欧洲以外。局部中断造成如此广泛影响的主要原因是远程对等连接的日益普及。
Conclusion & Comments
link -> AS -> operator -> PoP,中断信号产生后,根据影响的AS可以一级一级聚合来判断中断发生的等级
PoP-level的outage检测,存在一个很大的问题,就是无法有一个标准的ground-truth来评判检测结果
这种检测方法也无法确定中断发生的原因
文章在技术手段上没有提出很大的创新,但是在工程上做出了很大的贡献,特别是前期数据准备阶段的工作